is a blog about design, technology and culture written by Khoi Vinh, and has been more or less continuously published since December 2000 in New York City. Khoi is currently Principal Designer at Adobe. Previously, Khoi was co-founder and CEO of Mixel (acquired in 2013), Design Director of The New York Times Online, and co-founder of the design studio Behavior, LLC. He is the author of “How They Got There: Interviews with Digital Designers About Their Careers”and “Ordering Disorder: Grid Principles for Web Design,” and was named one of Fast Company’s “fifty most influential designers in America.” Khoi lives in Crown Heights, Brooklyn with his wife and three children.
A real danger for many longstanding brands is inadvertently talking only to their most dedicated customers and mistaking that dialogue for being representative of the larger market. You don’t want to ignore your core constituency, of course—you want to make them feel cared for and invested in your success. But you also don’t want to confuse their feedback with that of other, more casual groups of users who have not yet drunken the Kool-Aid, so to speak.
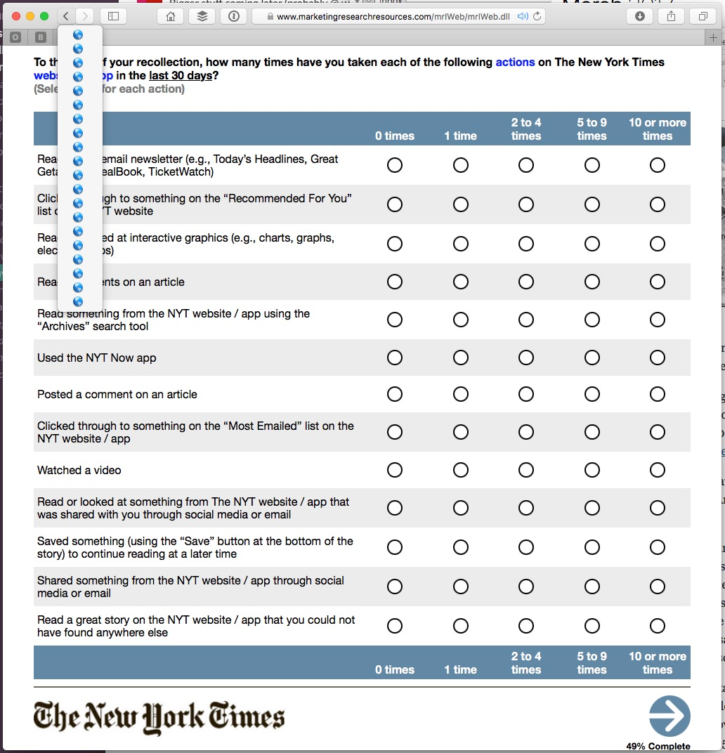
Here’s a good example that I encountered yesterday. In the course of one of my many daily visits to NYTimes.com I was asked to participate in a survey of user habits. That in and of itself is a problem: as a former employee of The New York Times, my opinion is biased and definitely not representative of “the average user.” I use the same account as I did when I was working there; it should have been easy enough to filter me out.
Worse, the survey is long. The sample screen shown here gives you a taste: plenty of text to read and plenty of options to parse. The progress indicator in the bottom left shows that this page is at nearly the exact midpoint, but the real context is shown in the list that I revealed by clicking and holding on the browser’s Back button. Each globe icon represents a step in the survey (the developers did not encode titles for each page, which is why they’re unlabeled.) I waded through about twenty screens before getting to this point, and there are about twenty more to go.
That’s a hefty proposition for users being surveyed. It’s frankly too much for everyone but a very, very dedicated kind of user, someone who either so intensely identifies with the brand (like me) or someone who is disproportionately angry (or even happy) about some recent interaction with the company. You could argue that this survey is aimed specifically at the most dedicated of Times readers, but even amongst that subset, only a few are going to have the energy or follow-through to complete the process. Other folks—folks who did not work at The Times or who have better things to do with their day—they’ll abandon this survey very early on.
The end result is likely going to be heavily skewed data which is perhaps worse than no data, because it gives you the mistaken impression that you’re working on concrete information when the exact opposite is true. These types of polls should be short and sweet and require little to no energy from its targeted participants. Or, better yet, the energy could be used to get out there and talk to real users.